-
WHAT WE DO
- CLINICAL SOLUTIONS
- SERVICES
-
WHO WE ARE
-
RESOURCES



")









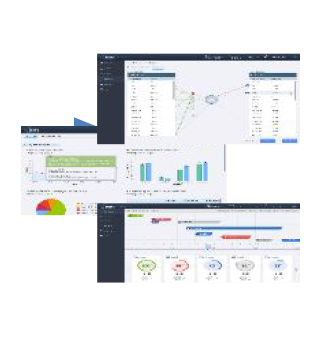
A one-stop-solution for all of biopharmaceutical industry’s needs including data integration, transformation, aggregation, quality management, enrichment, analytics and reporting.

A single, scalable, and integrated solution that is implantable in one project that is a one stop solution for data, metadata, reporting and analytics.

MDR’s ability to efficiently manage instream Enterprise level E2E processes and audit trails from a metadata perspective and interface with MaxisIT’s integrated platform products as well as third-party products

completely metadata-driven, drag-n-drop data integration, transformation, and standardization solution, which offers huge reusability and drives automation with required collaboration, control, and scalability

One solution supporting multiple analytics needs ranging from monitoring, descriptive, exploratory, trending, predictive and adaptive – all in one integrated platform.

Assured Credibility of results (per Good Statistical Practice) via: reproducible, transparent and validated analysis; and a collaborative environment

Ubiquitous analytical sandbox environment designed for “Data Scientists” enabling them with the desired flexibility for conducting Exploratory, Predictive and Prescriptive Analytics specifically for Data Sciences purposes.

RBM solution has the ability to function as the single point of contact for understanding, monitoring, and mitigating risks, by employing out-of-the-box integrated RBM workflows.

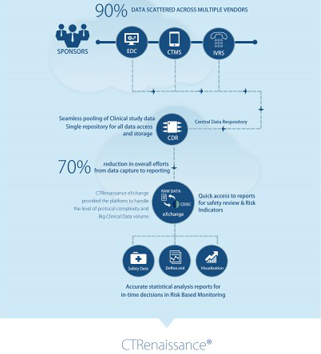
Data Services model reduces manual processing thereby increasing the quality of data with reduced overall cost. Further, it allows standardized and centralized environment for end-to-end data management needs, ensuring the credibility of clinical data.

It is productive on the Integrated Platform for Clinical Development and Data Sciences environment, where they can leverage the workflows and increase the level of automation.

Incorporates high availability features including automated failover of instances, fully redundant host, network, storage hardware, and enterprise class Storage Area Networks to increase performance and reliability.

Single and multiple study based usage which provides managed services, support services and professional services.

OBSAASE is built-on validated environment as a configurable platform to inherit the validity to newly created artifacts and is made available via high performance, and highly available computing architecture infused by on-demand scalability.
An increasing desire for integration across verticals and patient-centric business processes means that metadata automation and collaboration matters more than ever. The historical definition of metadata is “data about data”, or “metadata is structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use, or manage an information resource”.
Access to data and key information for the purpose of Analytics has been a constant in the Pharmaceutical / Life Sciences / Health Care industries, and this has been true for a great deal of time.
Clinical trials must be properly monitored by sponsors, not only to protect the participants in the trials but also to ensure trial data integrity for regulatory compliance. Capable of adapting to the level of risk, Risk Based Quality Management (RBQM) can prove highly effective for onsite-monitoring. This is why sponsors believe RBQM is the way […]
From cars to computers, with every product we use, a tipping point comes when it becomes ineffective or obsolete and needs replacement with a shinier and better performing version. Most of us resist change, and would rather plod along, using the old and underperforming version until it breaks down on us and refuses to go […]
Clinical trials demand time and money from drug sponsors and patience from participants. From start to finish, they average a time window of 9 years and cost of $1.3 B. The real challenge is that 12% of clinical trials succeed while the rest leave dashed hopes behind, begging the question as to what can make […]
Efforts to bring new therapies to market have never been more challenging than today, with drug sponsors striving to manage dynamic, transformative changes in drug development. Advances in data mining and analysis are met by a growing number of data sources. At the same time, digitization has enabled the patient-centric design of trial protocols with […]
Wearables have come a long way from being just a part of the support system for insomniacs and fitness enthusiasts. Today, they form a part of digital health technologies and are maturing into sensor-based wearables which gather real-time data for clinical trials. The insights they offer into a patient’s health and fitness stream in 24x7x365, […]
This blog is the second in a 2-part series that discusses the increasing variety of data types and sources. The first installment described the increasing variability of sources, types, and formats. This blog focuses on the impact on the people, processes, and technology involved in clinical trials. The variety, volume, and velocity of data coming […]
This blog is the first in a 2-part series that discusses the increasing variety of data types and sources. The first installment describes the increasing variability of sources, types, and formats. The second installment discusses the impact on the people, processes, and technology involved in clinical trials. Emerging technologies are enabling clinical research teams to […]
This week I listened as a colleague in Clinical Operations spoke with an EDC vendor. The vendor boasted that lab data, which normally arrives separately from the sites’ patient data, could be integrated with the other site data and viewed as a single-source-of-truth for the clinical team. This got me thinking about what constitutes a […]
MaxisIT’s Technology Platform helps small to large biopharmaceutical organizations in their need to build a holistic insight mechanism based on authenticated and aggregated data for effective decision making within the planning, conduct, and submission phases of clinical trials. MaxisIT recently spent time speaking with business leaders from some of our client organizations. The exercise was part […]
Pharma companies face huge challenges with the variety and volume of data they receive from across their clinical trial portfolios. Core challenges faced in clinical trial management vary from study design optimization to targeted therapies to benefit-risk assessments to cost reduction. Then we have the need for increased access to a core primary asset or […]
Command centers today have evolved from being war rooms into digital interfaces, which provide a centralized accessibility, monitoring, and control over organizational processes, specific business processes or goals. Command centers help organizations to maintain remote control over a process or business as a whole to ensure that it functions as designed and does not allow […]
Technology adoption is reinventing the way clinical research professionals collect clinical data from diverse sources. Integrating the clinical data collected from a complex range of sources which include new and emerging data collection solutions to site-level data and data collected from wearables, Electronic Health Records and patient apps is quite the challenge presented today […]
Technology adoption and strategic revisions to processes are redefining clinical trials today. Data collection is taking new approaches, with data from wearables and mobile apps complementing the traditional modes of data collection. The challenge here extends beyond data collection, as the collected data from these diverse sources needs to be integrated and analyzed in real-time […]
The global pharmaceutical industry was pegged by some studies to reach USD 1.57 trillion by 2023, based on some market drivers, growth trends and current and upcoming challenges. Meeting these growth predictions will require the industry to master the management of clinical trials and plug the loopholes which were exposed only too well, by the […]
Many drug candidates and ongoing research studies into their efficacy received serious setbacks when COVID-19 resulted in the total closure of many trial study sites. There’s no saying when these studies will resume and bring deserving drug candidates to the market, to benefit a number of patients who need them, even today. This disruption to […]
As the world was brought to an abrupt halt, the importance of adopting digital technologies has become apparent in all spheres of life, especially so for industries. Will the healthcare and pharmaceutical industry is quickly adopt digital technologies, , in these turbulent times, to fulfill their duty of saving lives and to attain their business […]
According to the statistics posted on Worldometer, the world has 803,451 active cases, with 39,044 deaths. This makes COVID_19 preparedness of the highest priority now, turning all other activities non-urgent. This pandemic is taxing the healthcare system and its capabilities, in most countries of the world. The havoc being wrought upon the world by COVID-19 […]
The world has unwillingly come to a grinding halt, unsure of where to turn, with the impact of the pandemic COVID-19. Even as we submit to social distancing and lockdown requirements based on our geographic location, we are confident that ‘this too shall pass’ and we will resume our lives, ready to pick up where […]
The world today is caught in a real predicament, living through an apocalyptic scenario, in a daze of disbelief – if not outright denial. This is no fictional account from a Robin Cook bestseller, there isn’t a heroic protagonist stepping up to contain Covid-19. Although we aren’t questioning our chances of survival yet, most aspects […]
Hiring more manpower is not the answer to getting your clinical trials’ timelines back on track. If anything can help, that would be the adoption of technology and more specifically, AI. The new way to cut the timelines of clinical trials short is to leverage artificial intelligence to drive the processes. Manage Data to Manage […]
What would you expect from a platform which offers to manage your clinical trials? Would you expect timely access to as authoritative, standardized and aggregated clinical trial operations data as well as patient data from site, study to portfolio level? Would you need efficient trial oversight via remote monitoring, statistically assessed controls, data quality management, […]
As discussed in Part 1 and Part 2 of AI in Clinical Trials, to process a large and continuously flowing stream of data, the pharma industry will need to employ an equally swift platform to ingest, standardize and manage the data, i.e. a holistic clinical data management platform. With the help of AI, MaxisIT’s Clinical […]
In Part-1 we discussed the problem statement and the focus areas for clinical development. We also concluded that quick access to relevant information decides the efficiency of a clinical trial. Let us now see how AI can help. An end-to-end clinical data management platform powered by artificial intelligence is the right choice for streamlining, overseeing […]
According to visionary leader Steve Jobs, if one defines the problem correctly, that person almost has the solution. And here we are discussing AI as the bellwether solution to every business/operational challenge in this world. Throw in a few AI-related words and the conversation suddenly sounds futuristic and efficient. Sure, AI is already impacting us […]
In Part 1 and Part 2, we discussed the self-service analytics platform and its various components. In this part we will look into the important things to consider before implementing a self-service analytics platform. The historical way of representing clinical data includes spreadsheet driven models and custom SQL queries which not only increased development time […]
In Part 1 we introduced self-service analytics and discussed what an ideal self-service analytics platform should accomplish. In this part, we will be discussing the various components of a modern technology platform that enables self-service analytics. Data ingestion – In a clinical trial setting, both structured and unstructured data is available from an ever-expanding range […]
The pharmaceuticals and lifesciences industry is undergoing transformation at an unprecedented scale mainly due to the regulatory, diminishing margins, growing amount of data and push for AI. One way to keep up with this pace of change is to create a robust analytics infrastructure that will help sponsors organizations to share information more efficiently and […]
As clinical studies increase in complexity in a myriad of ways, a key question often asked is, “Is our ability to create complexity increasing faster than our ability to understand complexity?” This is an exciting time to be involved in the reporting of data and metrics on the performance of a clinical study. However, it […]
Increasing clinical development costs for drugs has been a concern for industry over the years and multidirectional efforts have been made to lower these costs through more efficient study management. Since monitoring accounts for a substantial proportion of the total study costs, major focus is towards lowering the monitoring costs through the analysis of risks […]
Post FDA’s final guidance on Risk Based Monitoring, Industry is transitioning from routine visits to clinical sites and 100% Source Data Verification to risk-based approaches to monitoring, focusing more on critical data elements by practicing Centralized Monitoring; relying more on technological advancements thus reducing trial cost and time significantly. The industry needs an out-of-the-box end […]
Clinical research is experiencing a revolution with a huge range of connected devices growing in popularity, with wearable and implantable devices across healthcare, fitness tracking and diet. Pharmaceutical companies sponsoring trials are incorporating these devices into ever more elaborate clinical trials, generating ever larger datasets, while sifting through social media streams and their own big […]
The role of Master Metadata Management (MDM) MDM is a technology-enabled discipline in which business and IT work together to ensure the uniformity, accuracy, stewardship, semantic consistency and accountability of the enterprise’s official, shared master data assets. The idea of Master Data focuses on providing unobstructed access to a consistent representation of shared information. How […]
Industry wide Clinical Trial collaborative efforts offers significant improvement over siloed individual databases in providing superior Patient Outcomes. The efforts however were still limited to Rare Disease categories and Data Sources resulting in limited Clinical Analyses and Insight. A Clinical Data Repository utilizing Big Data will enable Pharmaceutical Cos to utilize new Analytic techniques and […]
Clinical study designs are becoming increasingly complex. A growing number of studies are using adaptive designs and require decisions during the conduct of the study. At the same time there’s a growing demand for more amount of data, a larger variety of data types and time pressures on decision making. During clinical study conduct, scientists […]
SDV is a very expensive process due to the time required to go through all the data at the various investigator sites. However, if we can target the patients and specify items the CRAs should look at when they visit a site, then the CRAs can spend more time looking at the important data but […]
CDISC standards have become an integral part of the life science industry; nevertheless, we will have to continue to deal with clinical data in different legacy formats for some time in the future. While the use of purely CDISC-formatted data from the very beginning of a submission project is unproblematic, combining data in legacy format […]
Clinical organizations are under increasing pressure to execute clinical trials faster with higher quality. Subject data originates from multiple sources; CRFs collect data on patient visits, implantable devices deliver data via wireless technology. All this data needs to be integrated, cleaned and transformed from raw data to analysis datasets. This data management across multiple sources […]
Metadata enables exchange, review, analysis, automation and reporting of clinical data. Metadata is crucial for clinical research and standardization makes it powerful. Adherence of metadata to CDISC SDTM has become the norm, since the FDA has chosen SDTM as the standard specification for submitting tabulation data for clinical trials. Today, many sponsors expect metadata to […]
CDISC defines SEND as an implementation of the SDTM standard for nonclinical studies. SEND specifies a way to collect and present nonclinical data in a consistent format. SEND is one of the required standards for data submission to FDA. SEND = Standard for the Exchange of Nonclinical Data. Sponsors are currently focused on processes and […]
The drug development industry and regulatory agencies continue to struggle with implementing CDISC for both the study workflow and the submission review process. Several factors contribute to these ongoing challenges including limitations within the CDISC standards themselves and the inability to represent complex relationships across clinical information in limited tools such as Excel. In our […]
As the coordinator or manager of a clinical trial, you will have one simple goal: You would want your clinical trial to be successful. After all, it is your responsibility. However, to guarantee success, you need to be able to manage the project efficiently. It is of prime importance that, at any time during the […]
Things seem to be set in motion in clinical trial management when programmers ready to perform the analysis get their code-happy hands on the clinical study data – however, once the CROs drop the data off, how does it actually make the journey to the statistical programmer’s desktop? This is a critical process, but too […]
CDISC or Clinical Data Interchange Standards Consortium is a standards developing organization that supports data exchange in medical research to benefit the medical community. CDISC standards are free to use, international, and universal. However, small to medium size pharma companies have low adoption rates when it comes to adopting or implementing CDISC standards. Is this […]
Cloud-based systems eliminate huge investments into IT infrastructure with pay-as-you-go features. They help to reduce timelines, and enable the hosting of clinical trial-related data in the cloud with secured systems which meet strict regulatory and compliance guidelines. They also make the transfer of real time data for analysis and track studies easy. This has made […]
Clinical trials that function on a global magnitude have clinical sites and patients across multiple geographies. The very nature of clinical trials brings opportunities as well as some challenges, wherein the clinical data spread across the globe adds more complexities to this. Amid these convoluted multiplicities, the element of BYOD, wearable technology, and mHealth applications […]
With all due respect to the Herculean task undertaken by the Human Genome Project which cost over 3 billion dollars and spanned over fifteen years. The time needed to sequence the human genome was recently pared back to just 26 hours. Though I was not involved in this project directly, it is definitely an inspiration […]
With the complexity involved in regulatory and exploratory reporting for clinical trials, adding another element of SCE might seem overwhelming to some of the stakeholders in the clinical development team, particularly the biometrics team, management and investors. I, would however, contend that it is necessary to help reduce data to reporting cycle time and related […]
We find diverse clinical data sources, heterogeneous clinical data formats, the multitude of drug outputs and much more, within a drug development process. A highly agile and adaptable clinical environment supported by cohesive clinical data management and reporting processes can only accommodate and respond to the perpetuating mutations and metamorphosis in the process. Who can […]
I keep seeing more and more headlines which report on genome-wide dissection of genetics, high-throughput technologies, genetic modifications and other biomedical breakthroughs in drug development. All of them lead to one common catalyst — a data-intensive drug development and discovery model used by the successful team. But, such a model can only thrive in the […]
In order to avoid a constrained growth model, an R&D focused organization needs to empower its business stakeholders with cross-functional insight and portfolio-level information management strategy. Prospective solutions should allow necessary roll-down and roll-up flexibilities in identifying potential indicators of change (e.g. risk and/or opportunities) and its impact, while taking decisions with confidence. To mobilize […]
The global clinical data analytics market will be worth $13.8 billion by 2023 according to a ResearchAndMarkets report. It identifies the growing popularity of EMRs as the key driver of this growth. However the clinical development industry is still grappling with the problem of disintegrated and non-standardized critical trial processes which is further handicapped by […]
There has been a collective realization throughout the industry that the key clinical trial data management processes must show efficiency, continuous compliance, scalability, sustainability and measurable productivity gains that, over time, will transform the research and development processes used to develop new drugs. Industry leaders are addressing this problem by delivering solutions that can address […]
Clinical Trial Data managers today are hampered by a number of data gaps that require filling. Let’s take a quick look at the clinical trial data management areas in which the drug development industry is facing problems. If any of these sound familiar, you might be in need of help! Data Capturing & Aggregation: The […]
Since the first few citations of registered and structured clinical data in the 1940s, the methods of capturing clinical data, use and application of clinical data, global inclusions, and role of payers, users and regulators have evolved. At present, the Clinical Data universe comprises the siloed internal and external data sources within clinical development processes. […]
How an Integrated Clinical Development Platform Helped a Client Tear Down Clinical Data Silos and Improve Decision-Making. The Challenge – Faced with a mélange of clinical data and challenges in standardization which hamstring their decision-making capabilities, our client decided to implement an integrated platform-based strategy that would help them to Ingest data from diversified sources […]
The demand for wearables and sensors in clinical trials is on the rise. Pharma companies are increasingly challenged with both rising costs and the need to find novel ways to differentiate the drugs they are developing. One such way is by accessing the clinical data collected using remote medical devices. By leveraging remote medical devices, […]
Clinical teams are often stuck in a vicious cycle of static report requests, impeding clinical data review and database lockdown. The main struggle is to unify and analyze data across domains. If data is not uniform, it restricts access to complete clinical information which, in turn, will affect the decision making on safety and efficacy. […]
A closer look at the most path-breaking enterprise cloud technologies, which have come about in the recent past, reveals that they are addressing either efficiency issues (time, cost or both), or a need which has been unaddressed or are solving for a latent need. Participants in the clinical trial industry have not been early adopters […]
Celebrate the Past and Invent the Future with MaxisIT® at the DIA 50th Annual Meeting, June 15-19 2014 in San Diego, CA! Hosted this year at the San Diego Convention Center, the DIA Annual Meeting celebrates its 50th anniversary, as a community of life science professionals across all disciplines gather to discuss, share and network […]
MaxisIT brings you the CTOS – to provide clinical trial oversight far superior to any CTMS or EDC system – to integrate, manage and gain control over the clinical trial metadata across your clinical trial portfolio.
")
A one-stop-solution for all of biopharmaceutical industry’s needs including data integration, transformation, aggregation, quality management, enrichment, analytics and reporting.
A single, scalable, and integrated solution that is implantable in one project that is a one stop solution for data, metadata, reporting and analytics.
MDR’s ability to efficiently manage instream Enterprise level E2E processes and audit trails from a metadata perspective and interface with MaxisIT’s integrated platform products as well as third-party products
completely metadata-driven, drag-n-drop data integration, transformation, and standardization solution, which offers huge reusability and drives automation with required collaboration, control, and scalability
One solution supporting multiple analytics needs ranging from monitoring, descriptive, exploratory, trending, predictive and adaptive – all in one integrated platform.
Assured Credibility of results (per Good Statistical Practice) via: reproducible, transparent and validated analysis; and a collaborative environment
Ubiquitous analytical sandbox environment designed for “Data Scientists” enabling them with the desired flexibility for conducting Exploratory, Predictive and Prescriptive Analytics specifically for Data Sciences purposes.
RBM solution has the ability to function as the single point of contact for understanding, monitoring, and mitigating risks, by employing out-of-the-box integrated RBM workflows.
Data Services model reduces manual processing thereby increasing the quality of data with reduced overall cost. Further, it allows standardized and centralized environment for end-to-end data management needs, ensuring the credibility of clinical data.
It is productive on the Integrated Platform for Clinical Development and Data Sciences environment, where they can leverage the workflows and increase the level of automation.
Incorporates high availability features including automated failover of instances, fully redundant host, network, storage hardware, and enterprise class Storage Area Networks to increase performance and reliability.
Single and multiple study based usage which provides managed services, support services and professional services.
OBSAASE is built-on validated environment as a configurable platform to inherit the validity to newly created artifacts and is made available via high performance, and highly available computing architecture infused by on-demand scalability.
An increasing desire for integration across verticals and patient-centric business processes means that metadata automation and collaboration matters more than ever. The historical definition of metadata is “data about data”, or “metadata is structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use, or manage an information resource”.
Access to data and key information for the purpose of Analytics has been a constant in the Pharmaceutical / Life Sciences / Health Care industries, and this has been true for a great deal of time.
Clinical trials must be properly monitored by sponsors, not only to protect the participants in the trials but also to ensure trial data integrity for regulatory compliance. Capable of adapting to the level of risk, Risk Based Quality Management (RBQM) can prove highly effective for onsite-monitoring. This is why sponsors believe RBQM is the way […]
From cars to computers, with every product we use, a tipping point comes when it becomes ineffective or obsolete and needs replacement with a shinier and better performing version. Most of us resist change, and would rather plod along, using the old and underperforming version until it breaks down on us and refuses to go […]
Clinical trials demand time and money from drug sponsors and patience from participants. From start to finish, they average a time window of 9 years and cost of $1.3 B. The real challenge is that 12% of clinical trials succeed while the rest leave dashed hopes behind, begging the question as to what can make […]
Efforts to bring new therapies to market have never been more challenging than today, with drug sponsors striving to manage dynamic, transformative changes in drug development. Advances in data mining and analysis are met by a growing number of data sources. At the same time, digitization has enabled the patient-centric design of trial protocols with […]
Wearables have come a long way from being just a part of the support system for insomniacs and fitness enthusiasts. Today, they form a part of digital health technologies and are maturing into sensor-based wearables which gather real-time data for clinical trials. The insights they offer into a patient’s health and fitness stream in 24x7x365, […]
This blog is the second in a 2-part series that discusses the increasing variety of data types and sources. The first installment described the increasing variability of sources, types, and formats. This blog focuses on the impact on the people, processes, and technology involved in clinical trials. The variety, volume, and velocity of data coming […]
This blog is the first in a 2-part series that discusses the increasing variety of data types and sources. The first installment describes the increasing variability of sources, types, and formats. The second installment discusses the impact on the people, processes, and technology involved in clinical trials. Emerging technologies are enabling clinical research teams to […]
This week I listened as a colleague in Clinical Operations spoke with an EDC vendor. The vendor boasted that lab data, which normally arrives separately from the sites’ patient data, could be integrated with the other site data and viewed as a single-source-of-truth for the clinical team. This got me thinking about what constitutes a […]
MaxisIT’s Technology Platform helps small to large biopharmaceutical organizations in their need to build a holistic insight mechanism based on authenticated and aggregated data for effective decision making within the planning, conduct, and submission phases of clinical trials. MaxisIT recently spent time speaking with business leaders from some of our client organizations. The exercise was part […]
Pharma companies face huge challenges with the variety and volume of data they receive from across their clinical trial portfolios. Core challenges faced in clinical trial management vary from study design optimization to targeted therapies to benefit-risk assessments to cost reduction. Then we have the need for increased access to a core primary asset or […]
Command centers today have evolved from being war rooms into digital interfaces, which provide a centralized accessibility, monitoring, and control over organizational processes, specific business processes or goals. Command centers help organizations to maintain remote control over a process or business as a whole to ensure that it functions as designed and does not allow […]
Technology adoption is reinventing the way clinical research professionals collect clinical data from diverse sources. Integrating the clinical data collected from a complex range of sources which include new and emerging data collection solutions to site-level data and data collected from wearables, Electronic Health Records and patient apps is quite the challenge presented today […]
Technology adoption and strategic revisions to processes are redefining clinical trials today. Data collection is taking new approaches, with data from wearables and mobile apps complementing the traditional modes of data collection. The challenge here extends beyond data collection, as the collected data from these diverse sources needs to be integrated and analyzed in real-time […]
The global pharmaceutical industry was pegged by some studies to reach USD 1.57 trillion by 2023, based on some market drivers, growth trends and current and upcoming challenges. Meeting these growth predictions will require the industry to master the management of clinical trials and plug the loopholes which were exposed only too well, by the […]
Many drug candidates and ongoing research studies into their efficacy received serious setbacks when COVID-19 resulted in the total closure of many trial study sites. There’s no saying when these studies will resume and bring deserving drug candidates to the market, to benefit a number of patients who need them, even today. This disruption to […]
As the world was brought to an abrupt halt, the importance of adopting digital technologies has become apparent in all spheres of life, especially so for industries. Will the healthcare and pharmaceutical industry is quickly adopt digital technologies, , in these turbulent times, to fulfill their duty of saving lives and to attain their business […]
According to the statistics posted on Worldometer, the world has 803,451 active cases, with 39,044 deaths. This makes COVID_19 preparedness of the highest priority now, turning all other activities non-urgent. This pandemic is taxing the healthcare system and its capabilities, in most countries of the world. The havoc being wrought upon the world by COVID-19 […]
The world has unwillingly come to a grinding halt, unsure of where to turn, with the impact of the pandemic COVID-19. Even as we submit to social distancing and lockdown requirements based on our geographic location, we are confident that ‘this too shall pass’ and we will resume our lives, ready to pick up where […]
The world today is caught in a real predicament, living through an apocalyptic scenario, in a daze of disbelief – if not outright denial. This is no fictional account from a Robin Cook bestseller, there isn’t a heroic protagonist stepping up to contain Covid-19. Although we aren’t questioning our chances of survival yet, most aspects […]
Hiring more manpower is not the answer to getting your clinical trials’ timelines back on track. If anything can help, that would be the adoption of technology and more specifically, AI. The new way to cut the timelines of clinical trials short is to leverage artificial intelligence to drive the processes. Manage Data to Manage […]
What would you expect from a platform which offers to manage your clinical trials? Would you expect timely access to as authoritative, standardized and aggregated clinical trial operations data as well as patient data from site, study to portfolio level? Would you need efficient trial oversight via remote monitoring, statistically assessed controls, data quality management, […]
As discussed in Part 1 and Part 2 of AI in Clinical Trials, to process a large and continuously flowing stream of data, the pharma industry will need to employ an equally swift platform to ingest, standardize and manage the data, i.e. a holistic clinical data management platform. With the help of AI, MaxisIT’s Clinical […]
In Part-1 we discussed the problem statement and the focus areas for clinical development. We also concluded that quick access to relevant information decides the efficiency of a clinical trial. Let us now see how AI can help. An end-to-end clinical data management platform powered by artificial intelligence is the right choice for streamlining, overseeing […]
According to visionary leader Steve Jobs, if one defines the problem correctly, that person almost has the solution. And here we are discussing AI as the bellwether solution to every business/operational challenge in this world. Throw in a few AI-related words and the conversation suddenly sounds futuristic and efficient. Sure, AI is already impacting us […]
In Part 1 and Part 2, we discussed the self-service analytics platform and its various components. In this part we will look into the important things to consider before implementing a self-service analytics platform. The historical way of representing clinical data includes spreadsheet driven models and custom SQL queries which not only increased development time […]
In Part 1 we introduced self-service analytics and discussed what an ideal self-service analytics platform should accomplish. In this part, we will be discussing the various components of a modern technology platform that enables self-service analytics. Data ingestion – In a clinical trial setting, both structured and unstructured data is available from an ever-expanding range […]
The pharmaceuticals and lifesciences industry is undergoing transformation at an unprecedented scale mainly due to the regulatory, diminishing margins, growing amount of data and push for AI. One way to keep up with this pace of change is to create a robust analytics infrastructure that will help sponsors organizations to share information more efficiently and […]
As clinical studies increase in complexity in a myriad of ways, a key question often asked is, “Is our ability to create complexity increasing faster than our ability to understand complexity?” This is an exciting time to be involved in the reporting of data and metrics on the performance of a clinical study. However, it […]
Increasing clinical development costs for drugs has been a concern for industry over the years and multidirectional efforts have been made to lower these costs through more efficient study management. Since monitoring accounts for a substantial proportion of the total study costs, major focus is towards lowering the monitoring costs through the analysis of risks […]
Post FDA’s final guidance on Risk Based Monitoring, Industry is transitioning from routine visits to clinical sites and 100% Source Data Verification to risk-based approaches to monitoring, focusing more on critical data elements by practicing Centralized Monitoring; relying more on technological advancements thus reducing trial cost and time significantly. The industry needs an out-of-the-box end […]
Clinical research is experiencing a revolution with a huge range of connected devices growing in popularity, with wearable and implantable devices across healthcare, fitness tracking and diet. Pharmaceutical companies sponsoring trials are incorporating these devices into ever more elaborate clinical trials, generating ever larger datasets, while sifting through social media streams and their own big […]
The role of Master Metadata Management (MDM) MDM is a technology-enabled discipline in which business and IT work together to ensure the uniformity, accuracy, stewardship, semantic consistency and accountability of the enterprise’s official, shared master data assets. The idea of Master Data focuses on providing unobstructed access to a consistent representation of shared information. How […]
Industry wide Clinical Trial collaborative efforts offers significant improvement over siloed individual databases in providing superior Patient Outcomes. The efforts however were still limited to Rare Disease categories and Data Sources resulting in limited Clinical Analyses and Insight. A Clinical Data Repository utilizing Big Data will enable Pharmaceutical Cos to utilize new Analytic techniques and […]
Clinical study designs are becoming increasingly complex. A growing number of studies are using adaptive designs and require decisions during the conduct of the study. At the same time there’s a growing demand for more amount of data, a larger variety of data types and time pressures on decision making. During clinical study conduct, scientists […]
SDV is a very expensive process due to the time required to go through all the data at the various investigator sites. However, if we can target the patients and specify items the CRAs should look at when they visit a site, then the CRAs can spend more time looking at the important data but […]
CDISC standards have become an integral part of the life science industry; nevertheless, we will have to continue to deal with clinical data in different legacy formats for some time in the future. While the use of purely CDISC-formatted data from the very beginning of a submission project is unproblematic, combining data in legacy format […]
Clinical organizations are under increasing pressure to execute clinical trials faster with higher quality. Subject data originates from multiple sources; CRFs collect data on patient visits, implantable devices deliver data via wireless technology. All this data needs to be integrated, cleaned and transformed from raw data to analysis datasets. This data management across multiple sources […]
Metadata enables exchange, review, analysis, automation and reporting of clinical data. Metadata is crucial for clinical research and standardization makes it powerful. Adherence of metadata to CDISC SDTM has become the norm, since the FDA has chosen SDTM as the standard specification for submitting tabulation data for clinical trials. Today, many sponsors expect metadata to […]
CDISC defines SEND as an implementation of the SDTM standard for nonclinical studies. SEND specifies a way to collect and present nonclinical data in a consistent format. SEND is one of the required standards for data submission to FDA. SEND = Standard for the Exchange of Nonclinical Data. Sponsors are currently focused on processes and […]
The drug development industry and regulatory agencies continue to struggle with implementing CDISC for both the study workflow and the submission review process. Several factors contribute to these ongoing challenges including limitations within the CDISC standards themselves and the inability to represent complex relationships across clinical information in limited tools such as Excel. In our […]
As the coordinator or manager of a clinical trial, you will have one simple goal: You would want your clinical trial to be successful. After all, it is your responsibility. However, to guarantee success, you need to be able to manage the project efficiently. It is of prime importance that, at any time during the […]
Things seem to be set in motion in clinical trial management when programmers ready to perform the analysis get their code-happy hands on the clinical study data – however, once the CROs drop the data off, how does it actually make the journey to the statistical programmer’s desktop? This is a critical process, but too […]
CDISC or Clinical Data Interchange Standards Consortium is a standards developing organization that supports data exchange in medical research to benefit the medical community. CDISC standards are free to use, international, and universal. However, small to medium size pharma companies have low adoption rates when it comes to adopting or implementing CDISC standards. Is this […]
Cloud-based systems eliminate huge investments into IT infrastructure with pay-as-you-go features. They help to reduce timelines, and enable the hosting of clinical trial-related data in the cloud with secured systems which meet strict regulatory and compliance guidelines. They also make the transfer of real time data for analysis and track studies easy. This has made […]
Clinical trials that function on a global magnitude have clinical sites and patients across multiple geographies. The very nature of clinical trials brings opportunities as well as some challenges, wherein the clinical data spread across the globe adds more complexities to this. Amid these convoluted multiplicities, the element of BYOD, wearable technology, and mHealth applications […]
With all due respect to the Herculean task undertaken by the Human Genome Project which cost over 3 billion dollars and spanned over fifteen years. The time needed to sequence the human genome was recently pared back to just 26 hours. Though I was not involved in this project directly, it is definitely an inspiration […]
With the complexity involved in regulatory and exploratory reporting for clinical trials, adding another element of SCE might seem overwhelming to some of the stakeholders in the clinical development team, particularly the biometrics team, management and investors. I, would however, contend that it is necessary to help reduce data to reporting cycle time and related […]
We find diverse clinical data sources, heterogeneous clinical data formats, the multitude of drug outputs and much more, within a drug development process. A highly agile and adaptable clinical environment supported by cohesive clinical data management and reporting processes can only accommodate and respond to the perpetuating mutations and metamorphosis in the process. Who can […]
I keep seeing more and more headlines which report on genome-wide dissection of genetics, high-throughput technologies, genetic modifications and other biomedical breakthroughs in drug development. All of them lead to one common catalyst — a data-intensive drug development and discovery model used by the successful team. But, such a model can only thrive in the […]
In order to avoid a constrained growth model, an R&D focused organization needs to empower its business stakeholders with cross-functional insight and portfolio-level information management strategy. Prospective solutions should allow necessary roll-down and roll-up flexibilities in identifying potential indicators of change (e.g. risk and/or opportunities) and its impact, while taking decisions with confidence. To mobilize […]
The global clinical data analytics market will be worth $13.8 billion by 2023 according to a ResearchAndMarkets report. It identifies the growing popularity of EMRs as the key driver of this growth. However the clinical development industry is still grappling with the problem of disintegrated and non-standardized critical trial processes which is further handicapped by […]
There has been a collective realization throughout the industry that the key clinical trial data management processes must show efficiency, continuous compliance, scalability, sustainability and measurable productivity gains that, over time, will transform the research and development processes used to develop new drugs. Industry leaders are addressing this problem by delivering solutions that can address […]
Clinical Trial Data managers today are hampered by a number of data gaps that require filling. Let’s take a quick look at the clinical trial data management areas in which the drug development industry is facing problems. If any of these sound familiar, you might be in need of help! Data Capturing & Aggregation: The […]
Since the first few citations of registered and structured clinical data in the 1940s, the methods of capturing clinical data, use and application of clinical data, global inclusions, and role of payers, users and regulators have evolved. At present, the Clinical Data universe comprises the siloed internal and external data sources within clinical development processes. […]
How an Integrated Clinical Development Platform Helped a Client Tear Down Clinical Data Silos and Improve Decision-Making. The Challenge – Faced with a mélange of clinical data and challenges in standardization which hamstring their decision-making capabilities, our client decided to implement an integrated platform-based strategy that would help them to Ingest data from diversified sources […]
The demand for wearables and sensors in clinical trials is on the rise. Pharma companies are increasingly challenged with both rising costs and the need to find novel ways to differentiate the drugs they are developing. One such way is by accessing the clinical data collected using remote medical devices. By leveraging remote medical devices, […]
Clinical teams are often stuck in a vicious cycle of static report requests, impeding clinical data review and database lockdown. The main struggle is to unify and analyze data across domains. If data is not uniform, it restricts access to complete clinical information which, in turn, will affect the decision making on safety and efficacy. […]
A closer look at the most path-breaking enterprise cloud technologies, which have come about in the recent past, reveals that they are addressing either efficiency issues (time, cost or both), or a need which has been unaddressed or are solving for a latent need. Participants in the clinical trial industry have not been early adopters […]
Celebrate the Past and Invent the Future with MaxisIT® at the DIA 50th Annual Meeting, June 15-19 2014 in San Diego, CA! Hosted this year at the San Diego Convention Center, the DIA Annual Meeting celebrates its 50th anniversary, as a community of life science professionals across all disciplines gather to discuss, share and network […]
MaxisIT brings you the CTOS – to provide clinical trial oversight far superior to any CTMS or EDC system – to integrate, manage and gain control over the clinical trial metadata across your clinical trial portfolio.