-
WHAT WE DO
- CLINICAL SOLUTIONS
- SERVICES
-
WHO WE ARE
-
RESOURCES

Metadata enables exchange, review, analysis, automation and reporting of clinical data. Metadata is crucial for clinical research and standardization makes it powerful. Adherence of metadata to CDISC SDTM has become the norm, since the FDA has chosen SDTM as the standard specification for submitting tabulation data for clinical trials. Today, many sponsors expect metadata to be not just compliant to CDISC but also to their own standards. Creating metadata that is consistent and accurate at every point of time from setup until and after the database lock remains a challenge for operational clinical data management. Metadata repositories help in creating standardized metadata but it is just the beginning and there is a need for more.
THE NEED FOR QUALITY METADATA
Metadata is defined to be data about data, but is it that simple? No, there is much more to it and more so in the clinical world. Clinical metadata provides conceptual, contextual and process information which not only defines data but also gives insight into the relationship between data. Metadata enables exchange, review, analysis, automation and reporting of clinical data. Standardization helps exchange and use of metadata across different processes during the life cycle of a clinical trial at the conceptual level but there is a need for flexibility at the contextual level. The context is dynamic. Metadata Repositories (MDRs) address standardization at the conceptual level. Leveraging flexibility at the contextual level is what makes metadata more meaningful and usable. While it is clear that metadata is crucial to create high quality clinical databases, achieving high quality metadata continually remains a challenge for clinical data management.
CHALLENGES ON THE ROAD TO QUALITY METADATA
How do we make sure trial metadata is consistent with CDISC SDTM standards? What if the sponsors have their own standards and are actively involved in the review? How do we balance the diverse sponsor needs? How do we keep up with standards that are changing constantly? How do we make sure that the trial metadata is both accurate and consistent? And how do we do it efficiently and effectively, saving both time and costs? While all of these continue to be the major questions that need to be addressed at the conceptual level, they give rise to many more questions that need to be addressed at the contextual level. These questions trickle down to the role of a programmer who has to find answers and make day to day decisions to provide quality metadata. Most of the questions have been discussed and addressed quite often at the conceptual level suggesting the metadata driven approach and need for seamless integration of processes and people. But what do they mean for a programmer and how do they translate into day to day tasks for a programmer who actually creates the metadata? I would like to focus on and draw attention to the questions that arise at the contextual level and discuss a few scenarios a programmer is confronted with on a day-to-day basis while creating the clinical metadata.
Access to Metadata in Real-time
Today, sponsors are actively involved in the review of the clinical databases and expect high quality databases and metadata. Sponsors have their own checks for validating compliance which are run on every snapshot and expect no output. Since databases are set up in a test environment and with test data, quality metadata would translate to metadata that is consistent with the current data, which is test data. And the moment we go live, we are expected to provide metadata that is consistent with the live data. Most of the time, a snapshot of the database with accurate metadata is expected to be available on the day we go live. How do we make this possible given the time constraints? And it doesn’t stop there. Live data changes every day, and the snapshots sent to sponsors should always be consistent and compliant, which requires them to be accessible in real-time.
Standards that change
New versions of standards contribute to overall improvement of quality and broaden the scope of domains. New versions are ‘nice to haves’ and sponsors will always want them implemented. Upgrading to the latest standards while the clinical trial is ongoing and the database is already set up brings in challenges. Upgrading to the latest standard doesn’t just mean copying the latest version of the metadata standard from the MDR. Since all of the contextual metadata for the trial is set up, a programmer would aim to retain it where applicable and make the upgrades only where needed. How do we do this given the time and cost constraints? How do we achieve compliance both with the standards and the trial in such cases and also be efficient?
Conflict of Standards
Standards are changing and just when we think we have figured out mechanisms to cope with changes, we are confronted with the discrepancies between standards, discrepancies between sponsor and CDISC standards, and discrepancies between ‘the’ standards. One such example would be: Dataset Column length requirement by the FDA. We have all seen the ‘Variable length is too long for actual data’ error on Pinnacle21. Compliance is always questioned when there are discrepancies. Discrepancies as such need to be reported and addressed within very short frames of time and with a rationale. It is not easy to convince sponsors to ignore a Pinnacle21 error.
Non-DM datasets
Datasets that are not generated by data management but are part of the submission package are Non-DM datasets. Datasets that are not part of the database when it is set up but are part of the submission package are to be dealt with for most clinical trials. Examples of such datasets are PC, PD, PP and so on. It is the responsibility of the programmer to make sure the metadata for all these datasets is complete and consistent. In case of blinded trials, these datasets are only delivered on the day of lock. Having such Non-DM datasets added to the rest of the datasets and delivering accurate metadata for these datasets on the day of lock is quite a task. What makes it difficult is the fact that you get to see the datasets for the first time on the day of lock when we are always running short of time and finding issues that need to be fixed right away. These datasets only add to the pressure. How can the consistency be checked for in such cases when the datasets are not part of the database and you cannot run all those checks which you would otherwise run on your database against the standard repositories? Will validating the datasets and running Define.xml on Pinnacle21 suffice? These are some of the few scenarios, every programmer encounters while a clinical trial runs its course. These happen to be more critical for early phase trials where trials last for very short periods of time and need to go through all of the workflows any other trial would but at a pace that is 10 times faster. Everything here needs to happen ‘on the go’ without compromising on quality.
IS QUALITY METADATA CONTINUALLY ACHIEVABLE?
To achieve quality metadata continually, MDRs or Metadata repositories should be generic, integrated, current, and historical. In order to accommodate the variety of sponsor needs, hierarchical MDRs need to be implemented with focus on standardization and reuse. The hierarchical nesting should be in the order of CDISC SDTM, SPONSOR/SGS STANDARD, THERAPEUTIC AREA, and CLINICAL TRIAL METADATA. This would be the first step to creating and providing sponsors with quality metadata that is consistent with both standards and clinical data right from the setup until and after the database lock and thus accurate at every point of time.
About MaxisIT
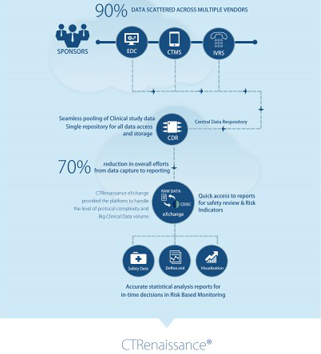
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of delivering Patient Data Repository, Clinical Operations Data Repository, Metadata Repository, Statistical Computing Environment, and Clinical Development Analytics via our integrated clinical development platform-; which delivers timely access to study specific as well as standardized and aggregated clinical trial operations as well as patient data, allows efficient trial oversight via remote monitoring, statistically assessed controls, data quality management, clinical reviews, and statistical computing.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is a purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Dashboards in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate”.
11 May 2018