-
WHAT WE DO
- CLINICAL SOLUTIONS
- SERVICES
-
WHO WE ARE
-
RESOURCES

With the complexity involved in regulatory and exploratory reporting for clinical trials, adding another element of SCE might seem overwhelming to some of the stakeholders in the clinical development team, particularly the biometrics team, management and investors. I, would however, contend that it is necessary to help reduce data to reporting cycle time and related costs; further it will improve the turnaround time involved in statistical computing, review, and approval cycles as well as offer a significant improvement in everyone’s ability to manage clinical data and access regulatory submission standard clinical data as well as reporting deliverables with required controls.
So, let me elaborate on ‘What is a Statistical Computational Environment?’.
What is an SCE?
When I review the definition of Statistical Computational Environment (SCE) as “a data repository of source code, input data, and output with compliance features such as version-control of SCE elements, reusable programming ability, and links to the clinical data management system.”, to me, it is almost self-explanatory why your clinical trials should be nurtured in an SCE.
While the definition reveals some of the most apparent reasons to instill a clinical trial into an SCE, there are many other compelling, and not so evident aspects which makes an SCE imperative for your trial. An SCE also consists of a structured programming environment that eases project management by enabling workflows, an operational analysis data repository that optimizes data standardization, and a metadata-driven architecture containing information about data and status of various processes, while streamlining it for compliance and transparency.
Why is an SCE so imperative?
Here are a few intersections according to my observation that capacitate clinical trials to stay more in alignment with not just the FDA criteria, but also the organizational vision.
Mastering Reproducibility
Statistical reproducibility is about providing detailed information about the choice of statistical tests, model parameters, threshold values, etc. It concerns the pre-registration of study design to prevent p-value hacking and other manipulations.
With the ability to reproduce the workflow that includes code and data used to validate the decisions made using research documents, the clinical trial team would save enormous amounts of time. To create and deliver newer drugs, with older formulae and data, SCE would allow access to pre-existing methods and results. This means other colleagues can approach new applications with a minimum of effort.
Site Selection
Trial and error site selection for clinical trials has disabled the research from creating a validated research foundation that can avoid large unwarranted costs and time lags. Disappointing numbers that say 80% of trials fail even before they meet enrollment while an investor has to spend almost $20,000 to 30,000 on an average on site selection signify the importance of site selection. Apart from this, researchers also have to deal with poor qualification of a site.
All these challenges can be answered by developing a data-driven site selection approach that not only fulfills an existing clinical trial, but also all the clinical trials to come in the future for a similar area of study.
Faster Approvals and Regulatory Compliance
FDA has been greatly instrumental in convincing clinical trial sponsors to use metadata and a unified format to submit for approval. To fulfill CDISC and other criteria, a clinical trial has to run in a statistical computational environment. Apart from this regulatory framework, there are many others that require creation and maintenance of metadata. It not only keeps it legal, but also ensures faster go-to-market time and a reference point for future studies at an extremely low cost.
While these are some strategic reasons for clinical trials to maintain an aura of SCE, there are some functional reasons too.
Rising complexities in clinical trials also need more computational power. SCEs add agility to the researcher and stakeholders by allowing them to store, maintain, access and edit information on a common platform. These environments provide ease for Non-clinical and Clinical Pharmacology analysis, translational medicine and Predictive modeling & Simulation.
The mindset of such teams should, however, be to welcome an integrated approach in deploying SCEs. SCE combined with an integrated technology solution that processes data through a singular analytical framework can build a foundation for future clinical research.
MaxisIT
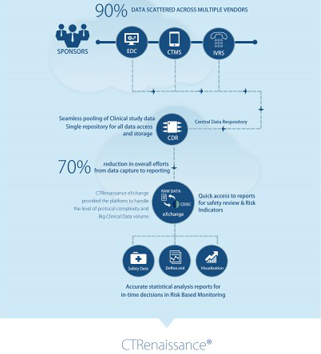
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of implementing solutions for improving Clinical Development Portfolio via an integrated platform-based approach; which delivers timely access to study specific as well as standardized and aggregated clinical data, allows efficient data quality management, clinical reviews, and statistical computing.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Analytics in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate.”
9 Jan 2018

7 May 2019