-
WHAT WE DO
- CLINICAL SOLUTIONS
- SERVICES
-
WHO WE ARE
-
RESOURCES

We find diverse clinical data sources, heterogeneous clinical data formats, the multitude of drug outputs and much more, within a drug development process. A highly agile and adaptable clinical environment supported by cohesive clinical data management and reporting processes can only accommodate and respond to the perpetuating mutations and metamorphosis in the process.
Who can save the day to match such adaptations? Statisticians and their supporting programming team is the answer. The statistical programming and analysis team that works in tandem with the discovery and development team can seamlessly deliver data analysis and even adhere to necessary clinical data standards only when they are supported by a data-savvy environment which includes infrastructure, tools, processes and mindset.
This is why I always recommend a Good Statistical Computational Environment (GSCE) to create viable and market-ready drug discoveries. Most importantly, it eliminates the chaos that is brought by data heterogeneity and adds traceability, data security, accessibility, auditability, efficiency and control to meet regulatory compliance needs, for the final user.
Why Good Statistical Computational Environment is as important as the process?
A good SCE is a consequence of two events — need to expedite drug discovery and obligation of adherence to FDA and other approval associations.
The patients and the medical community also accept a drug only when there is clinical trial data that proves its safety and efficacy. In fact, FDA has stipulations that require a drug to pass through the criteria with certain data proof made available as per their prescribed format and proforma with auditability, traceability, and via well-governed process. The FDA’s expectations for electronic submission guidance define what the FDA expects to receive: multiple types of data files, documentation, and programs—the major components of an analysis environment.
To match these, there are a slew of good practices recommended by ICH E9 which has prescribed best practices from a regulatory perspective. It emphasizes on the good statistical science of documented statistical operations which further ensure validity and integrity of pre-specified analyses, lending credibility to the results.
Data-driven processes such as Pharmacogenetic testing, Multigene panel testing, Targeted genetic testing for rare diseases and hereditary cancers, and human genome sequencing has seen the advantages of thriving in a statistical computational environment. They also have the high potential of receiving insurance coverage.
The major challenge that is curbed by ICH E9’s standardized formats is the diversity involved in different stages of clinical testing that focus on different statistical skill sets. The drug development process that begins with pharmacokinetic and pharmacodynamic studies requires early proof-of-concept supported by dose-ranging studies. Once, the drug passes through this stage, it is tested in the confirmatory phase for further efficacy and safety among a more heterogeneous population.
The life cycle development stage and the phase of post-marketing study are phases in the development process. Each phase with different data demands needs to be aligned with computations that can deliver relevant outputs.
How to begin envisioning a good SCE?
A good SCE needs to fulfil inclusion of empowerment to data-driven mindset, metadata-driven computing, technological scalability, analytical performance, an integrated approach with a single source of truth, role-based control processes and a continuum through the different stages of the process chain.
Most clinical data is processed among several programming activities which need to follow good statistical practices lined up by ICH E9. Apart from this, other bodies that offer a framework to develop a sound statistical environment are Clinical Data Interchange, Standards Consortium (CDISC) data standards, the CDISC analysis data model (ADaM) guidance, HL7 data standards, the harmonized CDISC-HL7 information model (BRIDG), electronic records regulations, FDA guidance for computerized systems, and electronic Common Technical Document (eCTD) data submissions.
ADaM guidance provides metadata standards for data and analyses. This enables statistical reviewers to understand, replicate, explore, confirm, and reuse the data and analyses. There’s no doubt that a transparent, reproducible, efficient, and validated approach to designing studies and to acquiring, analyzing, and interpreting clinical data will achieve a faster drug-to-market cycle.
Genetic counselors, hospital administrators, pharmacy advisory firms, academic studies, and consulting reports involved in an SCE also enjoy monetary benefits. Drugs that adhere to those standards also attract investor interest. Investor valuations for biotech companies are not purely based on profits but also, on long term potential, given the longer gestation period of drug development.
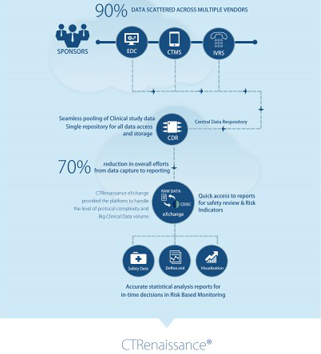
To reap these benefits, industry needs a Statistical Computing Environment that can support the derivation of statistical insights in a controlled, adaptable, auditable, and traceable manner utilizing an integrated approach that is based on metadata driven processes and relies on single-source of truth for data i.e. an enriched clinical data repository.
By achieving this, the records of decision stored from different stages of the process will keep the clinical cycle of the drug transparent, accessible and helps other scientists and clinical research stakeholders to conduct future research. This would retain the format of data intact, in its original form and at the same time does not interrupt the cohesiveness of the insight or information that the repository holds.
All put together, it indicates that the drug development process should incubate in a sound statistical computational environment for best results.
About MaxisIT:
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of implementing solutions for improving Clinical Development Portfolio via an integrated platform-based approach; which delivers timely access to study specific as well as standardized and aggregated clinical data, allows efficient data quality management, clinical reviews, and statistical computing.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Analytics in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate.”
14 Jul 2016

25 Mar 2021