-
WHAT WE DO
- CLINICAL SOLUTIONS
- SERVICES
-
WHO WE ARE
-
RESOURCES
The drug development industry and regulatory agencies continue to struggle with implementing CDISC for both the study workflow and the submission review process. Several factors contribute to these ongoing challenges including limitations within the CDISC standards themselves and the inability to represent complex relationships across clinical information in limited tools such as Excel.
In our personal lives we live in a connected world where all our information is linked together (e.g. Facebook, LinkedIn). We take the availability of information for granted and don’t realize what’s under the covers which links that information together. If you search for information about any disease a family member has, e.g. Alzheimer’s, you receive a LOT of interconnected information which helps you understand more about the disease and make better decisions about your family member.
Information within our clinical trials has the same dynamic relationships but unfortunately, we store our standards and data in just 2 dimensions with no robust way of linking that information.
THE PROBLEM – Separate data sets with variables and values.
The real problem lies in trying to pull this information together in a meaningful and clinically relevant way for a clinician who is trying to reach a conclusion. The problem arises when these connected and interrelated data points become disconnected and unrelated when we try to represent them.
Whereas technologies such as Google and Facebook integrate these relationships inside their data, in our world the institutional knowledge in our heads is what connects the data points. There are no electronic links between the data and nothing that really provides traceability likes everyone claims.
Our industry provides ‘specifications’ or ‘metadata’ that supposedly describe what our data will look like. But neither of them actually interacts with each other! This gives us this false sense of traceability or compliance that because we are checking the box saying we have specifications, we have better quality data. In reality, we are fooled into believing that our ‘specs’ give us quality data.
CONNECTING THE DOTS
The first step in connecting the dots is for the industry to stop using the word ‘metadata’. Most industries out there are not even sure what the word metadata means or use it in a very different context. The reality is that all the information we collect whether it is the value of a blood pressure reading, the name of a variable, or the length of numeric value is all data. Data that must be linked together in intelligent ways to really allow us to use our data.
We can connect this information in the form of a graph. The graphs I am talking about are the graph structures used by databases for semantic queries with nodes, edges and properties to represent and store data. A key concept of the system is the graph (or edge or relationship) directly relates data items in the store and the relationships allow data in the store to be linked together directly, and in many cases retrieved with one operation. This contracts a relational database. By baking the relationships into the database, institutional knowledge is not needed to connect the dots.
Our industry continues to struggle due to the limitations of the underlying models and the current technology used by industry to describe the multi-dimensional nature of clinical information. We will continue to struggle if we don’t look to embrace new ways of modeling our clinical information and really answering the questions we have in the clinical development process.
In our personal lives, we live in a connected world where all our information is linked together (e.g. Facebook, LinkedIn), yet we don’t take that simple step of realizing how we could represent the information in our clinical research world in the same way. In conclusion, we should stop trying to build ‘traceability’, ‘governance’, or ‘linkages’ in a world where the underlying models and existing technology can’t support it.
Patient Journey
It is important for pharmaceutical companies to understand the journey of the patient through the care pathway. They should understand the relevant patient population, the most relevant comparators and the potential drivers of effectiveness, which may create a gap between efficacy and effectiveness.
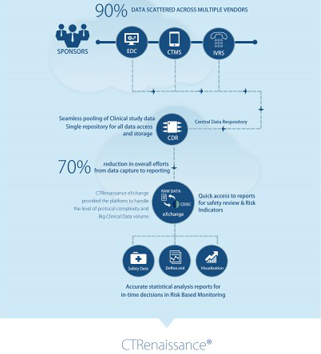
The key to mapping a patient’s journey in clinical trials is through documentation. Although various data capture systems support the clinical development, these systems are not typically connected to each other, thus making manual processes and individual data entry necessary. Ultimately, all information for the approval of a new pharmaceutical product is submitted electronically in one document. This creates an unusual situation, in which data are still recorded on paper documents but are also available online. For e.g., take the background of a patient which can often be found in the CTMS, the carrier, and IRT system. All of these systems receive the address via data upload – either from a list or by manual entry, both of which create the possibility of error. The job of a patient data repository is to connect such patient data stored in different systems like the CTMS, IRT, etc. and to enable optimal utilization for further analysis or documentation. Here are the advantages of using a patient data repository:
The adoption of a patient data repository has the potential to offer researchers a complete picture of the drug development journey – from manufacturing to the patient – with appropriate oversight and support.
About MaxisIT
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of delivering Patient Data Repository, Clinical Operations Data Repository, Metadata Repository, Statistical Computing Environment, and Clinical Development Analytics via our integrated clinical development platform-; which delivers timely access to study specific as well as standardized and aggregated clinical trial operations as well as patient data, allows efficient trial oversight via remote monitoring, statistically assessed controls, data quality management, clinical reviews, and statistical computing.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is a purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Dashboards in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate”.