-
WHAT WE DO
- CLINICAL SOLUTIONS
- SERVICES
-
WHO WE ARE
-
RESOURCES
CDISC standards have become an integral part of the life science industry; nevertheless, we will have to continue to deal with clinical data in different legacy formats for some time in the future. While the use of purely CDISC-formatted data from the very beginning of a submission project is unproblematic, combining data in legacy format with CDISC standardized data presents considerable challenges and therefore requires careful planning and special attention.
Scenario 1: “The files you sent are kaput“
XPT files cannot be opened in MS Word. This may seem funny but illustrates a challenge the industry is constantly facing.
Outside the clinical data science world, there is very little understanding of what needs to be done with clinical data for a regulatory submission to the FDA.
Regulatory Affairs departments are hesitant to approach the FDA outside the mandatory milestones. But with legacy data, it is important to contact the agencies with a sound data concept early to leave enough time for data preparation.
The pre-NDA / BLA meetings are usually too late for this discussion and should focus on important science aspects rather than data structures. Requests for the “full CDISC package” with a clean CDISC-Validator log often lead to some unnecessary effort.
Scenario 2: Analysis Datasets ≠ XPT Compliant
Starting Position – Data from multiple studies was analyzed using legacy formats. Dataset and variable names were too long for direct conversion to XPT format.
Possible Solution – Dataset and variable names need to be carefully renamed and standardized across all studies. Programs should be generated and submitted to map data back and forth between the data structures. Old and new names need to be documented in the DEFINE document.
Scenario 3: Comparing Original Results against Mapped Data Project Outline
For many projects only legacy raw data, legacy analysis data and original analysis results are available. Data preparation, analysis programs, and data definition documentation are missing. The customer needs a re-mapping of the legacy raw data to SDTM followed by the creation of CDISC compliant ADaM datasets. As a final QC step analysis results need to be recreated based on ADaM datasets and compared to original analysis results.
QC Result – We often see that discrepancies between the original and the re-programmed analysis emerge. Because of the lack of additional information on the original analysis, the resolution and documentation of findings is extremely time-consuming.
Potential Issues:
Scenario 4: Documentation
More often than not empty folders find their way into the folder tree. Sufficient documentation is key for reviewers to understand where the data came from and how it was processed.
Annotated CRFs and DEFINE documents are needed not only for SDTM data but also for legacy data.
Do not overload single documents. If more information is needed to understand certain aspects of the data, e.g. derivation of the key efficacy parameter, provide documents in addition to the reviewer’s guide and the define document, KISS — keep it short and simple and easy to understand
To Conclude
Every submission project is unique and needs careful planning to avoid costly delays
About MaxisIT
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of implementing solutions for improving Clinical Development Portfolio via an integrated platform-based approach; which delivers timely access to study specific as well as standardized and aggregated clinical trial operations as well as patient data, allows efficient trial oversight via remote monitoring, statistically assessed controls, data quality management, clinical reviews, and statistical computing. Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is a purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Dashboards in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate”.
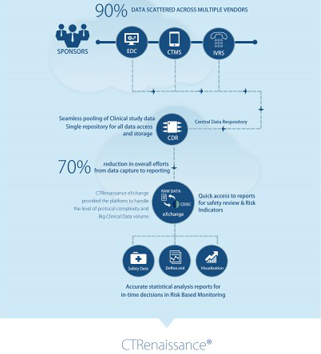
Clinical organizations are under increasing pressure to execute clinical trials faster with higher quality. Subject data originates from multiple sources; CRFs collect data on patient visits, implantable devices deliver data via wireless technology. All this data needs to be integrated, cleaned and transformed from raw data to analysis datasets. This data management across multiple sources is on the critical path to successful trial execution, and submission.
DEALING WITH BIG DATA
SDTM data provides a powerful tool for cross study analysis, and can include various types of external data from labs, ECGs and medical devices. Wearable devices are becoming more popular, and can even be included in patient treatment regimens. Once confirmed, these data can provide fantastic insights into patient data and population health. This ‘big’ data can allow researchers to observe drug reactions in larger populations than those under study, and aligning with genetic data could even reduce wasted treatment cycles. In the digital age, our attitude to information is changing. The traditional model of data capture and supply, using an EDC system with multiple integrations has shifted downstream. Rather than being at the very center of this picture, EDC has shifted left slightly: companies now expect their clinical systems to act as a hub for all of the information relevant to their drug on trial, and are searching for a single source of the truth, whatever the data source.
DATA WAREHOUSING AND STANDARDIZED DATA
Growing volumes of data, global operations and increasing regulatory scrutiny are encouraging pharmaceutical companies and healthcare providers to develop Clinical Data Warehouses. Data warehouses can be a mine of information in a data-rich business environment, and can greatly enhance data transparency and visibility. The interoperability of systems is increasing along with interchange standards, and real world data is being collected more widely than ever before. Data warehouses are often used to aggregate data from multiple transactional systems. Such systems may have data structures designed for collection, and not be aligned with the reporting standard. Typically this data is transformed and then loaded into a central data model that has been optimized for analysis, for example, market research or data mining.
It is possible to design a Clinical Data Warehouse that follows the model of a traditional data warehouse with a single well-defined data model into which all clinical data are loaded. This can create a powerful tool allowing cross study analysis at many levels. Data is never deleted or removed from the warehouse, and all changes to data over time are recorded. The main features of a reporting standard must be ease of use and quick retrieval. SDTM is a mature, extensible and widely understood reporting standard with clearly specified table relationships and keys. The key relationships can be used to allow users to select clinical data from different reporting domains without an understanding of the relationships between domains. SDTM also allows users to create their own domains to house novel and as yet unpublished data types, so we can maintain the principles above for any data type, allowing powerful cross domain reports to be created interactively.
AUTOMATED DATA LOADING AND CONFORMANCE TO SDTM
Data may be loaded from the source transactional systems in a number of ways. With EDC, new studies are continually brought online, and may be uploaded repeatedly. Most warehouse systems include a number of interfaces to load data. Many also supply APIs to allow external programs to control the warehouse in the same way as an interactive user. A combination of robust metadata, consistent data standards and naming conventions can allow automated creation of template driven warehouse structures, and dedicated listener programs can automatically detect files, and automate data loading.
The SDTM table keys enable incremental loading, where only records changed in the source system are updated in the warehouse, saving disk space. We can also use the SDTM keys in our audit processing, and use them to identify deleted records in incrementally loaded data pools. SDTM conversion, data pooling at Therapeutic Area and Compound level, and Medical Dictionary re-coding can be handled automatically in the warehouse in the reporting standard. Use of SDTM facilitates the pooling of studies to the maximum version available, accommodating all of the studies in previous versions without destructive changes which would affect the warehouse audit trail.
Uses of a Clinical Data Warehouse include:
Each of these can deliver value to a customer, but each requires consistent data structures, in a format that can be easily understood by the warehouse consumers.
INTEGRATION AND RECONCILIATION OF SAFETY AND DEVICE DATA
A Clinical Data Warehouse may also be connected to a transactional Safety system. This, coupled with the SDTM data warehouse can allow reconciliation of the two data sources, a crucial task as the Clinical studies are locked and reported. Automated transformations can account for the different vocabularies in the two systems, and the records can be paired together in a dashboard. The dashboards themselves can be configured to highlight non-matching records, and also to allow data entry to track comments, and acceptance of insignificant differences. Reconciliation involves both the Clinical and Safety groups, but could also be carried out by CRO users responsible for the studies. This enhances collaboration between the sponsor and CRO, and provides an audited central secure location to capture comments. Security is paramount in an open system, and the warehouse’s security model is designed to allow CRO users to only see the studies they have been assigned to, hiding other clinical studies from the dashboards and selection prompts. As a serious adverse event must be reported within 24 hours, it is possible that that event could be reconciled against the clinical data the following day. MHealth data can be integrated automatically using the IoT Cloud service, with patients automatically enrolled into an EDC study. This can be reconciled with CRF data and automatically loaded to the Business Intelligence layer.
TO CONCLUDE
SDTM can be of huge benefit to the users of a Clinical Data Warehouse system, allowing data pooling for storage, audit and reporting. Use of data standards has already transformed Clinical research. The next generation of eClinical Software should place those standards in front of programmers, inside the tools they use every day, and allow them to automate transformations to and from review and submission models, respond quickly to regulatory inquiries on current and historical data, generate automated definition documents and support a wide range of data visualization tools. Study component reusability and automatic documentation together enable clinical organizations to have greater clarity on what has been done to get from source (e.g. EDC, labs data) to target (e.g. SDTM) – to turn on the light in the black box.
Ultimately, leveraging standard, re-usable objects accelerates study setup, and combined with automation reduces manual processes, and increases traceability.
MaxisIT’s Clinical Development platform integrates a best in class data management platform, allowing clinical trial sponsors to automatically load and control data from EDC and various external sources, transform this from the collection standards into SDTM without user input, and provide the SDTM data to dynamic, near real-time analyses which can be compiled into internet-facing dashboards.
About MaxisIT
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of delivering Patient Data Repository, Clinical Operations Data Repository, Metadata Repository, Statistical Computing Environment, and Clinical Development Analytics via our integrated clinical development platform-; which delivers timely access to study specific as well as standardized and aggregated clinical trial operations as well as patient data, allows efficient trial oversight via remote monitoring, statistically assessed controls, data quality management, clinical reviews, and statistical computing.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is a purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Dashboards in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate”.
Metadata enables exchange, review, analysis, automation and reporting of clinical data. Metadata is crucial for clinical research and standardization makes it powerful. Adherence of metadata to CDISC SDTM has become the norm, since the FDA has chosen SDTM as the standard specification for submitting tabulation data for clinical trials. Today, many sponsors expect metadata to be not just compliant to CDISC but also to their own standards. Creating metadata that is consistent and accurate at every point of time from setup until and after the database lock remains a challenge for operational clinical data management. Metadata repositories help in creating standardized metadata but it is just the beginning and there is a need for more.
THE NEED FOR QUALITY METADATA
Metadata is defined to be data about data, but is it that simple? No, there is much more to it and more so in the clinical world. Clinical metadata provides conceptual, contextual and process information which not only defines data but also gives insight into the relationship between data. Metadata enables exchange, review, analysis, automation and reporting of clinical data. Standardization helps exchange and use of metadata across different processes during the life cycle of a clinical trial at the conceptual level but there is a need for flexibility at the contextual level. The context is dynamic. Metadata Repositories (MDRs) address standardization at the conceptual level. Leveraging flexibility at the contextual level is what makes metadata more meaningful and usable. While it is clear that metadata is crucial to create high quality clinical databases, achieving high quality metadata continually remains a challenge for clinical data management.
CHALLENGES ON THE ROAD TO QUALITY METADATA
How do we make sure trial metadata is consistent with CDISC SDTM standards? What if the sponsors have their own standards and are actively involved in the review? How do we balance the diverse sponsor needs? How do we keep up with standards that are changing constantly? How do we make sure that the trial metadata is both accurate and consistent? And how do we do it efficiently and effectively, saving both time and costs? While all of these continue to be the major questions that need to be addressed at the conceptual level, they give rise to many more questions that need to be addressed at the contextual level. These questions trickle down to the role of a programmer who has to find answers and make day to day decisions to provide quality metadata. Most of the questions have been discussed and addressed quite often at the conceptual level suggesting the metadata driven approach and need for seamless integration of processes and people. But what do they mean for a programmer and how do they translate into day to day tasks for a programmer who actually creates the metadata? I would like to focus on and draw attention to the questions that arise at the contextual level and discuss a few scenarios a programmer is confronted with on a day-to-day basis while creating the clinical metadata.
Access to Metadata in Real-time
Today, sponsors are actively involved in the review of the clinical databases and expect high quality databases and metadata. Sponsors have their own checks for validating compliance which are run on every snapshot and expect no output. Since databases are set up in a test environment and with test data, quality metadata would translate to metadata that is consistent with the current data, which is test data. And the moment we go live, we are expected to provide metadata that is consistent with the live data. Most of the time, a snapshot of the database with accurate metadata is expected to be available on the day we go live. How do we make this possible given the time constraints? And it doesn’t stop there. Live data changes every day, and the snapshots sent to sponsors should always be consistent and compliant, which requires them to be accessible in real-time.
Standards that change
New versions of standards contribute to overall improvement of quality and broaden the scope of domains. New versions are ‘nice to haves’ and sponsors will always want them implemented. Upgrading to the latest standards while the clinical trial is ongoing and the database is already set up brings in challenges. Upgrading to the latest standard doesn’t just mean copying the latest version of the metadata standard from the MDR. Since all of the contextual metadata for the trial is set up, a programmer would aim to retain it where applicable and make the upgrades only where needed. How do we do this given the time and cost constraints? How do we achieve compliance both with the standards and the trial in such cases and also be efficient?
Conflict of Standards
Standards are changing and just when we think we have figured out mechanisms to cope with changes, we are confronted with the discrepancies between standards, discrepancies between sponsor and CDISC standards, and discrepancies between ‘the’ standards. One such example would be: Dataset Column length requirement by the FDA. We have all seen the ‘Variable length is too long for actual data’ error on Pinnacle21. Compliance is always questioned when there are discrepancies. Discrepancies as such need to be reported and addressed within very short frames of time and with a rationale. It is not easy to convince sponsors to ignore a Pinnacle21 error.
Non-DM datasets
Datasets that are not generated by data management but are part of the submission package are Non-DM datasets. Datasets that are not part of the database when it is set up but are part of the submission package are to be dealt with for most clinical trials. Examples of such datasets are PC, PD, PP and so on. It is the responsibility of the programmer to make sure the metadata for all these datasets is complete and consistent. In case of blinded trials, these datasets are only delivered on the day of lock. Having such Non-DM datasets added to the rest of the datasets and delivering accurate metadata for these datasets on the day of lock is quite a task. What makes it difficult is the fact that you get to see the datasets for the first time on the day of lock when we are always running short of time and finding issues that need to be fixed right away. These datasets only add to the pressure. How can the consistency be checked for in such cases when the datasets are not part of the database and you cannot run all those checks which you would otherwise run on your database against the standard repositories? Will validating the datasets and running Define.xml on Pinnacle21 suffice? These are some of the few scenarios, every programmer encounters while a clinical trial runs its course. These happen to be more critical for early phase trials where trials last for very short periods of time and need to go through all of the workflows any other trial would but at a pace that is 10 times faster. Everything here needs to happen ‘on the go’ without compromising on quality.
IS QUALITY METADATA CONTINUALLY ACHIEVABLE?
To achieve quality metadata continually, MDRs or Metadata repositories should be generic, integrated, current, and historical. In order to accommodate the variety of sponsor needs, hierarchical MDRs need to be implemented with focus on standardization and reuse. The hierarchical nesting should be in the order of CDISC SDTM, SPONSOR/SGS STANDARD, THERAPEUTIC AREA, and CLINICAL TRIAL METADATA. This would be the first step to creating and providing sponsors with quality metadata that is consistent with both standards and clinical data right from the setup until and after the database lock and thus accurate at every point of time.
About MaxisIT
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of delivering Patient Data Repository, Clinical Operations Data Repository, Metadata Repository, Statistical Computing Environment, and Clinical Development Analytics via our integrated clinical development platform-; which delivers timely access to study specific as well as standardized and aggregated clinical trial operations as well as patient data, allows efficient trial oversight via remote monitoring, statistically assessed controls, data quality management, clinical reviews, and statistical computing.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is a purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Dashboards in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate”.
CDISC defines SEND as an implementation of the SDTM standard for nonclinical studies. SEND specifies a way to collect and present nonclinical data in a consistent format. SEND is one of the required standards for data submission to FDA. SEND = Standard for the Exchange of Nonclinical Data.
Sponsors are currently focused on processes and tools to receive, transform, store and create submission-ready SEND datasets. Their decisions and implementations are presently driven by the nature and variability of their data sources, understanding of SEND, determining how best to prepare and generate SEND datasets that will successfully load into NIMS, and putting in place quality assurance and data governance controls. These are key foundation steps in any implementation. Let us understand SEND compliance better through SEND implementation objectives, stakeholders, requirements, challenges, and opportunities.
SEND objectives
Sponsors need a shared vision for how SEND implementation will improve their R&D operations. More than implementing a new data format, it should:
SEND stakeholders
Here is a list of all clinical study stakeholders involved in SEND dataset creation and compliance.
Sponsor requirements
CROs can’t implement all SEND compliance requirements, even for sponsors outsourcing 100% of their nonclinical studies. Here are the requirements.
New elements of the sponsor’s study workflow include mapping internal LIMS data extracts to SEND data model, integrating external CRO datasets, dataset versioning and error handling, validation and submission of integrated datasets to FDA, creating Define Files, Validation Reports, and Study Data Review Guides and coordinated response to FDA queries across Study Reports and SEND datasets
Implementation challenges
SEND implementation is more complex and time-consuming than most sponsors expect! Here are a few of the challenges.
Implementation opportunities
The Potential efficiencies arising from SEND compliance include higher initial data quality and fewer protocol amendments with early access to interim datasets. Other benefits include automated dataset integration and versioning, automated study table generation, expedited FDA review and faster response to review questions
As the industry’s experience evolves, it is clear that sponsor implementations will extend into study planning and preparation stages, and expand the needs of their processes and tools to support submission requirements. It is only then that they will likely step into the realm of how they themselves can routinely consume and use standardized data in research and development activities.
MaxisIT
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of implementing solutions for improving Clinical Development Portfolio via an integrated platform-based approach; which delivers timely access to study specific as well as standardized and aggregated clinical trial operations as well as patient data, allows efficient trial oversight via remote monitoring, statistically assessed controls, data quality management, clinical reviews, and statistical computing. Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Analytics in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate”.