-
WHAT WE DO
- CLINICAL SOLUTIONS
- SERVICES
-
WHO WE ARE
-
RESOURCES
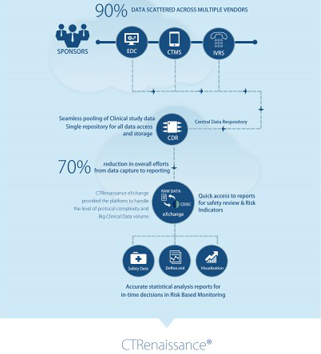
Clinical trials that function on a global magnitude have clinical sites and patients across multiple geographies. The very nature of clinical trials brings opportunities as well as some challenges, wherein the clinical data spread across the globe adds more complexities to this. Amid these convoluted multiplicities, the element of BYOD, wearable technology, and mHealth applications may seem overwhelming. However, they partially resolve the issue of multiplicity.
Let me explain how.
On time Data
The dispersed patient population refrains researchers and clinical trial practitioners from collecting real-time and on-time data necessary to draw timely insights for the drug development process. Eliminating follow-up visits to research centers, seamless clinical data collection, and reduced clinical data cost per patient are some of the advantages that have brought these personalized technologies accepted in the clinical trial process by practitioners, patients, and also the regulatory authorities such as the FDA.
In August 2017, the National Institutes of Health’s clinical trial database returned over 170 results for the search term ‘Fitbit’, over 300 for ‘wearable’ and over 440 studies 76 for ‘mobile app.’ This justifies the acceptance of BYOD, wearable technology, and mHealth applications in the clinical data collection process during clinical trials by the entire ecosystem.
While this is comforting news on one side; the researchers, investors and practitioners must deal with a different challenge when they step over to the other side. These technologies have led to device diversity which is followed by data diversity during clinical trials. With high diversity, the information systems and insight machines experience a continuous flow of data. By 2021, 504.65 million wearable devices are expected to be sold. Extremely useful clinical data can be derived and made available through them, but again not in a consumable form.
Many legal standards, statutory guidelines and recommendations for clinical data formats are already in place to resolve the issue of clinical data diversity and complexity. However, it is also a matter of transparency, speed to deploy meta-schema and the maintenance of clinical data repositories for the same. For future inquiry and research, maintaining a metadata repository is imperative. Apart from that delays and gaps in updating researchers and scientists of the new development and data points during the clinical trials would slow down the process drastically. It obviously has further adverse cost implications for both the investors and patients.
Clinical data diversity also brings in the complexity of managing a variety of clinical data formats. This creates heavy volume of clinical data which gets unmanageable in the absence of a robust statistical computational environment for clinical reporting.
In-Time Action
Instead of going back and forth to verify clinical data quality and timeliness out of a clinical trial, on-time clinical data renders necessary information to eliminate expensive iterations. On-time data facilitates in-time action; and in-time action helps fulfilling regulatory compliance and shortening the cycle of each clinical trial, while reducing costs.
A single platform that integrates, comprehends and interprets a variety of clinical data and clinical devices can turn such clinical data into insights. Seamless, transparent, and on-time insights into clinical data based on an aggregation and standardization across the clinical studies in a cloud-based clinical data repository, backed by AI and built around SCE, will enable all stakeholders involved in the clinical trial to act in-time. This would mitigate all risk and shorten your time to market.
MaxisIT
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of implementing solutions for improving Clinical Development Portfolio via an integrated platform-based approach; which delivers timely access to study specific as well as standardized and aggregated clinical data, allows efficient data quality management, clinical reviews, and statistical computing.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Analytics in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate.”
With all due respect to the Herculean task undertaken by the Human Genome Project which cost over 3 billion dollars and spanned over fifteen years. The time needed to sequence the human genome was recently pared back to just 26 hours. Though I was not involved in this project directly, it is definitely an inspiration to a healthcare IT entrepreneur like me.
So, what is the point I’m trying to make?
I’m referring to the gap between 15 years and 26 hours. In the future, this gap may diminish to a few seconds, bringing down the costs too. This gap is disappearing with the proliferation of technologies that can facilitate super computations for drug discoveries in nanoseconds and a research-conducive environment that aids more as a library than a mere repository.
While faster computation at lower average cost is one good reason I could share to emphasize the need for a Statistical Computational Environment (SCE); crowdsourcing, singularity of diverse clinical data formats, regulatory compliance, reference for future research, accountability, auditability, transparency, extensibility and scalability are a few other reasons for the need and adoption of SCE.
Looking back, what can you expect out of an SCE?
Statistical computations own certain features that are beneficial for clinical trials processes to thrive and support existing and prospective research. A few top-of-the-mind examples of this are:
Analytical excellence: SCE available on the cloud allows you to integrate different analytical applications, within the system or with third-party solutions. It also prepares an environment for execution and control of different programming languages such as SAS, R, Python and so on.
Analytics requires good quality of sourcing which is best achieved in a controlled environment that supervises and administers all information via secure logins, audit trails, versioning and role-based privileges and policies.
Workflow optimization: Heterogeneity in data is now a well-known attribute of clinical trials. This is unavoidable due to the inherent substance of age, geography, and media used in a clinical trial.
SCE provides a global workspace with a workflow for review and approval across multiple data sources. It allows teams from across the globe to access data, run computations, collaborate and share information using a single system. This also facilitates the tracing of existing clinical data back to its source.
Data standard support and clinical data preparation: Any format does not work, when you are preparing for an FDA approval. Metadata formats and clinical data stacking as per CDISC models – including SDTM, SEND, ADaM and Define 1.0 and 2.0, and other extensible custom models are supported.
Regulatory Compliance: This is not just about supporting data and format management for regulatory approvals, but also about providing quick access to the user in creating instant data outputs for an adaptive and agile submission process.
Some features that I strongly believe an SCE should possess.
Metadata management
Transparency is one of the aspects offered by an SCE to a clinical trial. Complexity in clinical data repository hierarchies and its sharing patterns, demand the presence of a clinical data management tool that can expedite reproduction of most relevant clinical data and in the most preferred format. This process includes clinical data storing, indexing, cataloging and aggregating, and accessing during a search.
Controlled Environment
Apart from administration and security management, the controls within the environment also enable data version control across multiple iterations, limited access to users, role-based access , and context-specific permissions. This is made available across all knowledge workers in areas such as pre-clinical, clinical operations and medical affairs to drive global collaboration between internal team members, consultants, contractors and development partners.
Extensibility
Lack of extensibility outside an SCE is a reason attributed to high attrition rates in the latter stages of clinical trials. SCE to a greater extent supports the success of commercializing useful therapies and molecular formulae. Drug development can be optimized when clinical data is integrated with the formats in which a scientist can access it. Owning an XIS platform at the core, the platform users can extract data from an XIS Server as well as other XML or Web service enabled source using a web-based application.
Scalability
Either in the case of classical pharmacology, forward pharmacology, reverse pharmacology or phenotypic drug discovery, scaling data and output swiftly is a factor yearned for.
Application of mass spectrometry for the elucidation of chemical structures from databases is a high-demand expectation of researchers and investors to make the most out of existing and approved chemical formulae. Implementation of Nuclear magnetic resonance spectroscopy (NMR) on existing molecular structures during a discovery process or clinical trial would lead to many other channels within the drug discovery process. SCE allows such branching out of discoveries, enabling researchers to add more value to a clinical trial.
MaxisIT
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of implementing solutions for improving Clinical Development Portfolio via an integrated platform-based approach; which delivers timely access to study specific as well as standardized and aggregated clinical data, allows efficient data quality management, clinical reviews, and statistical computing.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Analytics in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate.”
With the complexity involved in regulatory and exploratory reporting for clinical trials, adding another element of SCE might seem overwhelming to some of the stakeholders in the clinical development team, particularly the biometrics team, management and investors. I, would however, contend that it is necessary to help reduce data to reporting cycle time and related costs; further it will improve the turnaround time involved in statistical computing, review, and approval cycles as well as offer a significant improvement in everyone’s ability to manage clinical data and access regulatory submission standard clinical data as well as reporting deliverables with required controls.
So, let me elaborate on ‘What is a Statistical Computational Environment?’.
What is an SCE?
When I review the definition of Statistical Computational Environment (SCE) as “a data repository of source code, input data, and output with compliance features such as version-control of SCE elements, reusable programming ability, and links to the clinical data management system.”, to me, it is almost self-explanatory why your clinical trials should be nurtured in an SCE.
While the definition reveals some of the most apparent reasons to instill a clinical trial into an SCE, there are many other compelling, and not so evident aspects which makes an SCE imperative for your trial. An SCE also consists of a structured programming environment that eases project management by enabling workflows, an operational analysis data repository that optimizes data standardization, and a metadata-driven architecture containing information about data and status of various processes, while streamlining it for compliance and transparency.
Why is an SCE so imperative?
Here are a few intersections according to my observation that capacitate clinical trials to stay more in alignment with not just the FDA criteria, but also the organizational vision.
Mastering Reproducibility
Statistical reproducibility is about providing detailed information about the choice of statistical tests, model parameters, threshold values, etc. It concerns the pre-registration of study design to prevent p-value hacking and other manipulations.
With the ability to reproduce the workflow that includes code and data used to validate the decisions made using research documents, the clinical trial team would save enormous amounts of time. To create and deliver newer drugs, with older formulae and data, SCE would allow access to pre-existing methods and results. This means other colleagues can approach new applications with a minimum of effort.
Site Selection
Trial and error site selection for clinical trials has disabled the research from creating a validated research foundation that can avoid large unwarranted costs and time lags. Disappointing numbers that say 80% of trials fail even before they meet enrollment while an investor has to spend almost $20,000 to 30,000 on an average on site selection signify the importance of site selection. Apart from this, researchers also have to deal with poor qualification of a site.
All these challenges can be answered by developing a data-driven site selection approach that not only fulfills an existing clinical trial, but also all the clinical trials to come in the future for a similar area of study.
Faster Approvals and Regulatory Compliance
FDA has been greatly instrumental in convincing clinical trial sponsors to use metadata and a unified format to submit for approval. To fulfill CDISC and other criteria, a clinical trial has to run in a statistical computational environment. Apart from this regulatory framework, there are many others that require creation and maintenance of metadata. It not only keeps it legal, but also ensures faster go-to-market time and a reference point for future studies at an extremely low cost.
While these are some strategic reasons for clinical trials to maintain an aura of SCE, there are some functional reasons too.
Rising complexities in clinical trials also need more computational power. SCEs add agility to the researcher and stakeholders by allowing them to store, maintain, access and edit information on a common platform. These environments provide ease for Non-clinical and Clinical Pharmacology analysis, translational medicine and Predictive modeling & Simulation.
The mindset of such teams should, however, be to welcome an integrated approach in deploying SCEs. SCE combined with an integrated technology solution that processes data through a singular analytical framework can build a foundation for future clinical research.
MaxisIT
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of implementing solutions for improving Clinical Development Portfolio via an integrated platform-based approach; which delivers timely access to study specific as well as standardized and aggregated clinical data, allows efficient data quality management, clinical reviews, and statistical computing.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Analytics in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate.”
We find diverse clinical data sources, heterogeneous clinical data formats, the multitude of drug outputs and much more, within a drug development process. A highly agile and adaptable clinical environment supported by cohesive clinical data management and reporting processes can only accommodate and respond to the perpetuating mutations and metamorphosis in the process.
Who can save the day to match such adaptations? Statisticians and their supporting programming team is the answer. The statistical programming and analysis team that works in tandem with the discovery and development team can seamlessly deliver data analysis and even adhere to necessary clinical data standards only when they are supported by a data-savvy environment which includes infrastructure, tools, processes and mindset.
This is why I always recommend a Good Statistical Computational Environment (GSCE) to create viable and market-ready drug discoveries. Most importantly, it eliminates the chaos that is brought by data heterogeneity and adds traceability, data security, accessibility, auditability, efficiency and control to meet regulatory compliance needs, for the final user.
Why Good Statistical Computational Environment is as important as the process?
A good SCE is a consequence of two events — need to expedite drug discovery and obligation of adherence to FDA and other approval associations.
The patients and the medical community also accept a drug only when there is clinical trial data that proves its safety and efficacy. In fact, FDA has stipulations that require a drug to pass through the criteria with certain data proof made available as per their prescribed format and proforma with auditability, traceability, and via well-governed process. The FDA’s expectations for electronic submission guidance define what the FDA expects to receive: multiple types of data files, documentation, and programs—the major components of an analysis environment.
To match these, there are a slew of good practices recommended by ICH E9 which has prescribed best practices from a regulatory perspective. It emphasizes on the good statistical science of documented statistical operations which further ensure validity and integrity of pre-specified analyses, lending credibility to the results.
Data-driven processes such as Pharmacogenetic testing, Multigene panel testing, Targeted genetic testing for rare diseases and hereditary cancers, and human genome sequencing has seen the advantages of thriving in a statistical computational environment. They also have the high potential of receiving insurance coverage.
The major challenge that is curbed by ICH E9’s standardized formats is the diversity involved in different stages of clinical testing that focus on different statistical skill sets. The drug development process that begins with pharmacokinetic and pharmacodynamic studies requires early proof-of-concept supported by dose-ranging studies. Once, the drug passes through this stage, it is tested in the confirmatory phase for further efficacy and safety among a more heterogeneous population.
The life cycle development stage and the phase of post-marketing study are phases in the development process. Each phase with different data demands needs to be aligned with computations that can deliver relevant outputs.
How to begin envisioning a good SCE?
A good SCE needs to fulfil inclusion of empowerment to data-driven mindset, metadata-driven computing, technological scalability, analytical performance, an integrated approach with a single source of truth, role-based control processes and a continuum through the different stages of the process chain.
Most clinical data is processed among several programming activities which need to follow good statistical practices lined up by ICH E9. Apart from this, other bodies that offer a framework to develop a sound statistical environment are Clinical Data Interchange, Standards Consortium (CDISC) data standards, the CDISC analysis data model (ADaM) guidance, HL7 data standards, the harmonized CDISC-HL7 information model (BRIDG), electronic records regulations, FDA guidance for computerized systems, and electronic Common Technical Document (eCTD) data submissions.
ADaM guidance provides metadata standards for data and analyses. This enables statistical reviewers to understand, replicate, explore, confirm, and reuse the data and analyses. There’s no doubt that a transparent, reproducible, efficient, and validated approach to designing studies and to acquiring, analyzing, and interpreting clinical data will achieve a faster drug-to-market cycle.
Genetic counselors, hospital administrators, pharmacy advisory firms, academic studies, and consulting reports involved in an SCE also enjoy monetary benefits. Drugs that adhere to those standards also attract investor interest. Investor valuations for biotech companies are not purely based on profits but also, on long term potential, given the longer gestation period of drug development.
To reap these benefits, industry needs a Statistical Computing Environment that can support the derivation of statistical insights in a controlled, adaptable, auditable, and traceable manner utilizing an integrated approach that is based on metadata driven processes and relies on single-source of truth for data i.e. an enriched clinical data repository.
By achieving this, the records of decision stored from different stages of the process will keep the clinical cycle of the drug transparent, accessible and helps other scientists and clinical research stakeholders to conduct future research. This would retain the format of data intact, in its original form and at the same time does not interrupt the cohesiveness of the insight or information that the repository holds.
All put together, it indicates that the drug development process should incubate in a sound statistical computational environment for best results.
About MaxisIT:
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of implementing solutions for improving Clinical Development Portfolio via an integrated platform-based approach; which delivers timely access to study specific as well as standardized and aggregated clinical data, allows efficient data quality management, clinical reviews, and statistical computing.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Analytics in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate.”
I keep seeing more and more headlines which report on genome-wide dissection of genetics, high-throughput technologies, genetic modifications and other biomedical breakthroughs in drug development. All of them lead to one common catalyst — a data-intensive drug development and discovery model used by the successful team. But, such a model can only thrive in the presence of a sound Statistical Computational Environment (SCE).
To me, two elements drive the success of data management during clinical trials. One, is the ability to bring diverse clinical data forms in a single comprehensible format and the other is data driven in-depth knowledge to evaluate and validate the drug concept. The variety of clinical data forms interferes with security, accessibility, traceability and auditability which otherwise empower a clinical practitioner with better insights and adherence to regulatory compliance. These factors can be achieved by introducing the drug into a data driven environment, supported by a team with a similar data-intensive mindset who can build a Statistical Computational Environment (SCE). Using SCE, customers can establish control, auditability, traceability and gain efficiency without compromising on regulatory compliance.
NCBI also identifies that the publicly available biomedical info`1rmation is the basis for identifying the right drug target and creating a drug concept with true medical value. This has also helped them enhance their understanding about the pathophysiological mechanisms of diseases with the help of a data-driven clinical development model.
Prediction of metabolism, application of translational bioinformatics in reporting long-read amplicon sequencing of chronic myeloid leukemia and multi-drug resistant bacteria, and gene mutations are results of a data-intensive model. Apart from looking at data-intensive drug development models as an inhouse capability, I also see it as a competitive factor for R&D units and scientists eager to hit the market.
Here is why it is competitive. It has led to virtual drug development models that allow scientists to test and analyze a molecule even before the formulation stage. Eliminating challenges in the preclinical stages can reduce drug development costs and the lead time taken by each formula to transform into a druggable output. Nature, a popular science magazine, has confirmed through its research that the unprecedented challenges of a pharma business model can be met by shifting investments to the earlier stages of drug development and discovery.
To establish this approach, pharmaceutical and healthcare companies involved in drug development need to invite an integrated clinical data management approach. This involves defining clinical data sources for reliability and consistency, building a robust clinical data mining and warehousing infrastructure, and processing different insights useful to various stakeholders of the project and data users. Among these, McKinsey has pointed out that the first step itself takes about a year to complete.
Having been involved with multiple integrated clinical development platform projects, I have seen that drug-to-market lead time was brought down when the traditional drug development model was transformed into a data-intensive and technology-enabled environment that is integrated and automated to allow establishing focus on clinical data analysis and avoid mundane data processing tasks.
To gain a competitive edge, more and more successful drug development companies are moving towards and thriving in a data intensive drug development & discovery environment. Are you using a data-intensive drug development process or still stifled by the challenges of a traditional approach?
About MaxisIT
At MaxisIT, we clearly understand strategic priorities within clinical R&D, and we can resonate that well with our similar experiences of implementing solutions for improving Clinical Development Portfolio via an integrated platform-based approach; which delivers timely access to study specific as well as standardized and aggregated clinical data, allows efficient data quality management, clinical reviews, and statistical computing.
Moreover, it provides capabilities for planned vs. actual trending, optimization, as well as for fraud detection and risk-based monitoring. MaxisIT’s Integrated Technology Platform is purpose-built solution, which helps Pharmaceutical & Life sciences industry by “Empowering Business Stakeholders with Integrated Computing, and Self-service Analytics in the strategically externalized enterprise environment with major focus on the core clinical operations data as well as clinical information assets; which allows improved control over externalized, CROs and partners driven, clinical ecosystem; and enable in-time decision support, continuous monitoring over regulatory compliance, and greater operational efficiency at a measurable rate.”